Tutorial#
Introduction#
Documents often contain sensitive information (e.g. names, dates, identifiers, locations) that needs to be removed before documents can be used or shared further. Based on scientific research and personal experience, there is no ‘one-size-fits-all’-deidentifier that works for each language and domain. Rather, achieving good de-identification accuracy often requires some work and tailoring. The goal of the docdeid package is to make this work easier, and to make components of other de-identifiers reusable. Whether you only want need to use a regular expression to remove dates from text messages, or you want to use an advance machine learning model to scrub all potential sensitive information from medical discharge summaries, docdeid should make your work easier.
Before we dive into the tutorial, it’s worth emphasizing that docdeid is:
A framework for de-identification, with components for e.g. tokenizing, annotating, redacting and processing.
A library that includes only some basic re-usable implementations for the above components
And, that docdeid is not:
A de-identifier that can be applied out of the box
A machine learning library
This page contains a tutorial to get you started on the basics of creating a de-identifier using docdeid. If you need more in-depth technical details, the API is probably a good place to go afterwards.
Architechture overview#
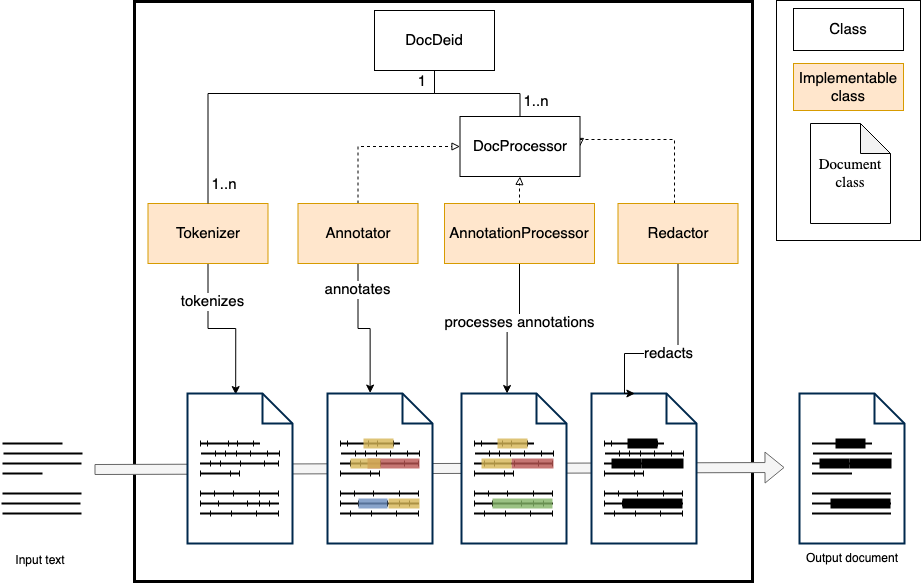
Creating a basic de-identifier#
Creating a new de-identifier is as easy as creating a DocDeid object, and adding components to it.
import docdeid as dd
deidentifier = dd.DocDeid()
In order to make the de-identifier do something, we need add one or more DocProcessor to it. Let’s first add an Annotator based on a regular expression, that detects names based on words that are capitalized.
from docdeid.process import RegexpAnnotator
import re
capital_pattern = re.compile("[A-Z][a-z]+")
name_annotator = RegexpAnnotator(regexp_pattern=capital_pattern, tag="name")
deidentifier.processors.add_processor("capitalized_words", name_annotator)
Next up, we need something that further processes the annotations that the RegexpAnnotator produces, to make sure they are replaced in the text.
from docdeid.process import SimpleRedactor
redactor = SimpleRedactor()
deidentifier.processors.add_processor("redactor", redactor)
And with that, we are already set to de-identify our first piece of text:
text = "Alice loves Bob, but Bob loves Clarice."
doc = deidentifier.deidentify(text)
>>> print(doc.annotations)
AnnotationSet({Annotation(text='Alice', start_char=0, end_char=5, tag='name', length=5),
Annotation(text='Bob', start_char=12, end_char=15, tag='name', length=3),
Annotation(text='Bob', start_char=21, end_char=24, tag='name', length=3),
Annotation(text='Clarice', start_char=31, end_char=38, tag='name', length=7)})
>>> print(doc.deidentified_text)
[NAME-1] loves [NAME-2], but [NAME-2] loves [NAME-3].
We managed to find the names in that piece of text without thinking too much about how the program runs, but devoted our attention to deciding what identifiable information to annotate, and what regexp would be suitable. That’s the power of frameworks!
Adding a tokenizer#
In the above example, we used a RegexpAnnotator, which does not need the text to be tokenized before use. Let’s extend the above example with another Annotator, which does lookup based on tokens. First let’s add a Tokenizer, in this case the built-in WordBoundaryTokenizer:
from docdeid.tokenize import WordBoundaryTokenizer
deidentifier.tokenizers['default'] = WordBoundaryTokenizer()
And, add another Annotator that annotates occupations, based on a set of available occupations. In a real world example, this set of occupations would probably be much longer to be useful.
from docdeid.process import SingleTokenLookupAnnotator
occupation_annotator = SingleTokenLookupAnnotator(
lookup_values={"carpenter", "librarian", "policeman", "student"},
tag="occupation"
)
deidentifier.processors.add_processor("occupation_lookup", occupation_annotator, position=1) # add it before the redactor
Now the de-identifier should also be able to pick any the occupations that occur in the text.
text = "Alice, who is a librarian, loves Bob, who is a carpenter"
doc = deidentifier.deidentify(text)
>>> print(doc.annotations)
AnnotationSet({Annotation(text='Alice', start_char=0, end_char=5, tag='name', length=5),
Annotation(text='Bob', start_char=33, end_char=36, tag='name', length=3),
Annotation(text='librarian', start_char=16, end_char=25, tag='occupation', length=9),
Annotation(text='carpenter', start_char=47, end_char=56, tag='occupation', length=9)})
>>> print(doc.deidentified_text)
[NAME-1], who is a [OCCUPATION-1], loves [NAME-2], who is a [OCCUPATION-2]
Again, we didn’t need to think about how to find and match tokens, we just need to find a tokenizer that is suitable for our text, and add an annotator for a new type of identifing information – docdeid handles the rest.
docdeid Components#
There are four components of docdeid that include some basic and re-usable implementations, and also define abstract classes to implement your own: Annotator, AnnotationProcessor, Redactor and Tokenizer. They are listed below.
Annotator#
The Annotator is arguably the most important component of a deidentifier, as it is responsible for finding and tagging identifiable information in text.
Class |
Description |
|---|---|
Abstract class, that allows your own implementations. Implement the |
|
Matches single tokens based on lookup values. |
|
Matches lookup values against tokens, where the |
|
Matches based on regular expressions |
|
Matches based on |
AnnotationProcessor#
An AnnotationProcessor can do some useful procesing on a set of annotations, like merging adjacent annotations, or resolving overlap among them.
Class |
Description |
|---|---|
Abstract class, that allows your own implementation. Implement the |
|
Resolves overlap among annotations. |
|
Merges annotations that are adjacent into one annotation. |
Redactor#
A Redactor modifies the text to a deidentified text, by redacting the annotations intext.
Class |
Description |
|---|---|
Abstract class, that allows your own implementation. Implement the |
|
Literally redacts all text. Might for example be used when an error is raised. |
|
Basic redactor, that replaces each annotation in text with TAG-n |
Tokenizer#
A Tokenizer splits the text into its atomic parts, called tokens.
Class |
Description |
|---|---|
Abstract class, that allows your own implementation. Implement the |
|
Tokenizes based on splitting on whitespaces ( |
|
Tokenizes based on word boundaries ( |
Implementing a component#
Implementing a component is straightforward, by inheriting from the abstract class and implementing the abstract method. For example, to implement a custom tokenizer that extracts words as tokens, the following code would suffice:
from docdeid.tokenize import Token, Tokenizer
import re
class MyCustomTokenizer(Tokenizer):
def _split_text(self, text: str) -> list[Token]:
return [
Token(text=match.group(0), start_char=match.start(), end_char=match.end())
for match in re.finditer(r"\w+", text)
]
It can now be added to a deidentifier in the same way any Tokenizer is added:
from docdeid import DocDeid
deidentifier = DocDeid()
deidentifier.tokenizers['my_custom'] = MyCustomTokenizer()
The Annotator, AnnotationProcessor and Redactor components can be implemented in a similar way as the above example.